
Building an autonomous decision making process for devices using machine learning.
Overview
The objective of this project is to build a decision making process for a device registered to the Industry Marketplace to automatically choose the best service requests based on matching eCl@ass capabilities.
What is the Industry Marketplace?
The Industry Marketplace is a vendor and industry-neutral platform, automating the trading of physical and digital goods and services. It combines the IOTA Tangle with standardized machine-readable contracts and an integrated decentralized identity system to enable actors to tender, bid and pay for services.
What is the eCl@ss?
eCl@ss is the data standard for the classification and unambiguous description of products and services.
What is IOTA Tangle?
The IOTA Tangle is a distributed ledger technology (DLT), recording data exchange in a secure and immutable log.
Set up Service Requester and Service Provider
I have followed following series of commands on a Raspberry Pi 4 (4GB RAM) to set environment for a service requester and service provider.
Clone the repositories for provider and requester at home directory
$ git clone https://github.com/iotaledger/industry-marketplace.git provider
$ git clone https://github.com/iotaledger/industry-marketplace.git requesterClone the repository for the python helper
$ git clone https://github.com/iota-community/industry-marketplace-python-helper.git python-helperSince requester and provider are the clones of the same repositories, we need to change one of them to listen on the port different than that of the default one.
$ cd ~/provider
$ git apply ../python-helper/patches/different_ports.patchStart the provider server app
$ cd ServiceApp
$ yarn run devStart the requester server app
$ cd ~/requester/ServiceApp
$ yarn run devInstall prerequisites for python helper
$ python3 -mvenv ~/myenv
$ source ~/myenv/bin/activate
$ cd ~/python-helper
$ pip install -r requirements.txtProvision the service requester and provider
$ python3 service_provider.py
$ python3 service_requester.pyWe can change the service requester and provider name and geo-location by changing relevant class variables in the service_provider.py and service_requester.py file before executing aforementioned commands.
For this project we do not require the web interface for the service requester and the service provider but to check everything works properly they can be handy.
Install scikit-learn
$ pip install sklearnFor this project I have chosen Drone connectivity provision service as listed in the operations.json and eclass.json provided by the python helper installation.
{
"id":"0173-1#01-BAF577#004",
"name": "Drone connectivity provision",
"description": "A drone with a mobile network connectivity equipment,
e.g., WiFi access point is requested to cover a specific
location in order to provide connectivity"
}The eCl@ss attributes for the service:
{
"0173-1#01-BAF577#004": {
"submodelElements": [{
"idShort": "duration [min]",
"modelType": "Property",
"value": "",
"valueType": "long",
"semanticId": "0173-1#02-AAA818#006"
},
{
"idShort": "maximum velocity at rated value [km/h]",
"modelType": "Property",
"value": "",
"valueType": "long",
"semanticId": "0173-1#02-AAB919#007"
},
{
"idShort": "max. monitoring radius [m]",
"modelType": "Property",
"value": "",
"valueType": "long",
"semanticId": "0173-1#02-AAI957#004"
},
{
"idShort": "2,4 GHz",
"modelType": "Property",
"value": "",
"valueType": "boolean",
"semanticId": "0173-1#07-ABA076#001"
},
{
"idShort": "5 GHz",
"modelType": "Property",
"value": "",
"valueType": "boolean",
"semanticId": "0173-1#07-ABA075#001"
},
{
"idShort": "energy consumption [kW/h]",
"modelType": "Property",
"value": "",
"valueType": "decimal",
"semanticId": "0173-1#02-AAF090#005"
},
{
"idShort": "location [lat, lng]",
"modelType": "Property",
"value": "",
"valueType": "string",
"semanticId": "0173-1#02-BAF163#002"
},
{
"idShort": "price",
"modelType": "Property",
"value": "",
"valueType": "integer",
"semanticId": "0173-1#02-AAO739#001"
}
]}
}The simple workflow of the Industry Marketplace is shown below (image credit: https://industrymarketplace.net).
In this project we will cover the workflow from the Call for Proposal to Sending Proposal back to the Requester. The eCl@ss attributes have semantic id which defines the attribute uniquely within the Marketplace. The process of making decision by human or by automating using hard-coded criteria works great but have severe limitations. The decision taken by human requires intervention and delays the overall process. The hard-coded criteria tries to automate this but have limitation to cover all mix of if/then/else cases. Here I propose a supervised machine learning technique which can covers the varieties of the use cases.
The idea is to use the sent or rejected proposal data which were decided by human agent in the recent past. For this exercise we selected Decision Trees which are a non-parametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features.
Data collection for training
The first and the most important step in a machine learning project is to collect the training data in such a way that it should cover most of the representative cases for a given recognition task. We do not have access to the proposal decision datasets so we will create a synthetic dataset. Since the market manager UI already creates the random data for a given service, we can use the same script to automate data generation. There is a wrapper script (generate_data/index.js) in the GitHub repository mentioned in the code section. To run this script we have to use following command:
$ git clone https://github.com/metanav/Marketplace_of_Devices.git
$ cd generate_data
$ npm install
$ npx babel-node index.js > data.jsonI have created a notebook (notebooks/Service_Provider_Decision_Tree_Classifier.ipynb) for training the generated data using Scikit-learn python library.
The data is processed for the training which looks like as follows:
The model target which is randomly generated either 0 (send proposal) or 1 (do not send proposal). In real scenario, these targets are real decision made by human agent or automated hard-coded criteria.
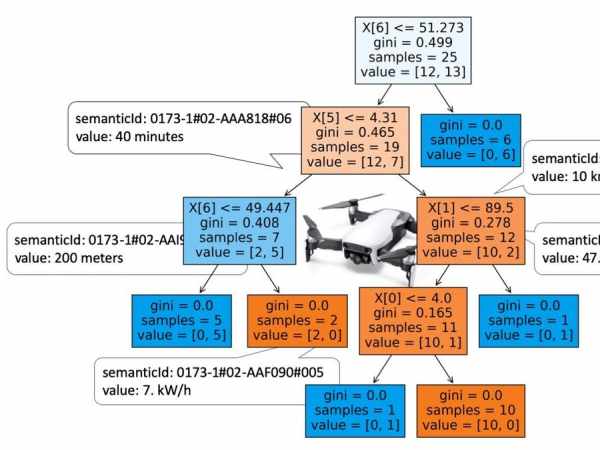
The trained model learned tree plot is shown below.
The trained model is used with the modified service_provider.py to make a decision whether proposal should be send or not.
Schematics
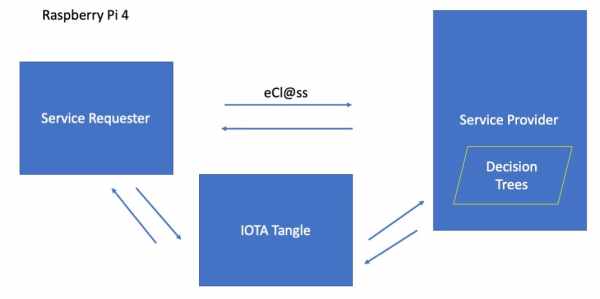
Source: Autonomous Marketplace Device