
Introduction
Access to internet and social media has resulted in an exponential increase of digital marketing and targeted advertising. One of the ways targeted advertising is achieved is through e-mails. Most of the times, the advertisement e-mails are unsolicited and provide no useful information to the users. These are better classified as spam. E-mail spam filtering is becoming all the more important and relevant in today’s digital age, given the massive amount of targeted advertising that’s in place. Even though e-mail spam filtering isn’t a new domain per se, of late it’s being treated from the perspective of Artificial Intelligence, particularly natural language processing and machine learning. This project targets the domain of e-mail spam filtering using machine learning. A classifier is trained using supervised Machine Learning algorithm called Support Vector Machine (SVM) to filter e-mail as spam or not spam. Each e-mail is converted to a feature vector. The SVM is trained on Raspberry Pi and the result displayed on the piTFT screen. In addition to displaying whether the e-mail is spam or not, the display also gives the user information about potential reasons for why the e-mail has been classified as spam. The database used for training is a toned-down version of the SpamAssassin Public Corpus; only the body of the e-mail is used. In addition, as a student, you can get a help with college homework if you don't have enough time on homework and you need to deal more with e-mail spam filtering.
Project Objectives
- Given an e-mail text, extract the features using natural language processing techniques and pass the features as input to SVM.
- Train SVM on the Raspberry Pi and use the model to classify incoming mails as spam or no-spam.
- Use the piTFT display system as User Interface to implement actions such as displaying spam or no-spam and providing information about why a particular e-mail has been classified as spam.
- Configure the Raspberry Pi to detect when a new e-mail has arrived in a gmail account and read this email, followed by e-mail pre-processing and feature extraction.
Design
The design of this project included implementation of the following –
- Fetching E-mail from a gmail account
- E-mail pre-processing using Natural Language Processing (NLP)
- Feature Extraction
- Training SVM
- Classification using trained model
- Implementing User Interface (UI) for piTFT display
Fetching E-mail from gmail account
First, we setup a gmail account ‘[email protected]'. Then we used fetchmail to receive e-mails on Raspberry Pi. Fetchmail is a client for IMAP and POP. We installed fetchmail using
sudo apt-get install fetchmail
Next, we created a file named .fetchmailrc in the home directory. This file has the contents –
poll imap.gmail.com
protocol IMAP
user "[email protected]" with password "*********" mda "/home/pi/myfetchmailparser.sh"
folder 'INBOX'
fetchlimit 1
keep
ssl
By default, fetchmail will pass the mail to port 25 on local host. When mda (mail delivery agent) is used, the mail will be passed to mda, which happens to be a script in our case. A limit of 1 has been set for fetchlimit. ‘keep’ ensures that the mail is not deleted after it has been read. Next, a file called myfetchmailparser.sh is created. This script writes the received email to a text file.
Filename=$(date +"%Y%m%d_%H%M%S_%N")
Outfile="/var/tmp/mail"$Filename
echo "" > $OutputFile
while read y
do
echo $y >> $Outfile
done
Since fetchmail doesn’t work on root, we set the user pi as the owner using the following commands –
sudo chown pi .fetchmailrc
sudo chown pi myfetchailparser.sh
Finally, the emails are read using –
fetchmail > /dev/null
When a new email arrives and fetchmail is executed, a filename with unique time stamp is created in /var/tmp directory, as shown below –

This file contains the email received. In addition to the body of the e-mail, fetchmail also extracts several other tags which are not needed for SVM model. These need to be removed. So, we executed the following commands to post-process the e-mail.
cd /var/tmp
filename=$(ls -lrt | tail -1 | awk '{print $9}')
cp $filename /home/pi/prj/forRPi/testmail.txt
cd /home/pi/prj/forRPi/
sudo chown pi testmail.txt
tail -n +76 testmail.txt > test76.txt
sudo chown pi test76.txt
head -n -6 test76.txt > currentmail.txt
sudo chown pi currentmail.txt
Using awk, ls, tail commands, the latest file written out in /var/tmp is identified. The name of the file is stored in $filename. This is copied to the project directory as testmail.txt. Then, using tail and head, the unwanted contents in testmail.txt are removed. Sample of the contents that are removed are shown below –

The file currentmail.txt is then passed to the python module for further pre-processing.
E-mail pre-processing using Natural Language Processing
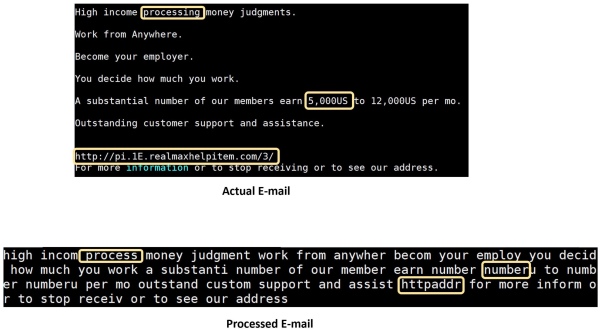
Pre-processing of e-mails involves converting the e-mail text to a form that is suitable for feature extraction. For example, spam e-mails are likely to contain URLs, asking the user to click on malicious links. These URLs will be different in every spam mail. One way to take care of URLs is to normalize them all – i.e. all URL links in the body of e-mail will be replaced by a string “httpaddr”. Similarly, we carried out many pre-processing steps on the e-mail text.
Email address normalizing: All email addresses in the body of the text are replaced with the text “emailaddr”. This can be done using :
line = re.sub(r"[^\s]+@[^\s]+","emailaddr",line)
Here, line refers to the current line being scanned in the e-mail body. re.sub is a function in the Regular Expressions package that matches a regular expression and substitutes it with another string. Here, the e-mail address in the form string@string is replaced with “emailaddr”
Conversion to lower-case letters: This step is carried out to ensure capitalization is ignored. The words “Include” and “include” must be treated the same. Conversion to lower-case is done using:
line = line.lower()
Normalizing numbers: All numbers must be treated the same way. For example, 1000 must be treated the same way as 100 or any other number. It’s only necessary that the SVM classifier understands that a number exists in the e-mail content. Magnitude of the number does not make an impact in spam classification. Hence all numbers are replaced with the word “number” using:
line = re.sub(r"\d","number",line)
Word Stemming: Stemming in the context of natural language processing refers to stripping the word to its root form. For example the words “includes”, “include”, “including”, “included” must be converted to the stemmed form “include”. This can be done using –
from nltk.stem.porter import PorterStemmer
porter = PorterStemmer()
stemmed = [porter.stem(word) for word in tokens]
Trimming of punctuations: All punctuations must be removed before extracting e-mail features. This can be done using natural language toolkit package in python –
from nltk.tokenize import word_tokenize
tokens = word_tokenize(text)
An example of actual e-mail and processed e-mail are shown in the figure below:
Feature Extraction
E-mail feature extraction is a key step in spam filtering, since the features predominantly determine the outcome of SVM. First step in e-mail feature extraction involves taking a decision about which words will be used for classification. If all words are included for classification, there’s a high likelihood of SVM model overfitting the training data. To avoid overfitting, words that rarely occur should not be considered. A general practice in spam filtering is to consider words that occur at least 100 times in the spam corpus vocabulary list. This results in about 2000 words that should be considered for classifier. Given processed e-mail text, each word can be mapped to the 2000-word vocabulary list. The vocabulary list has a number listed against each word, as shown below:
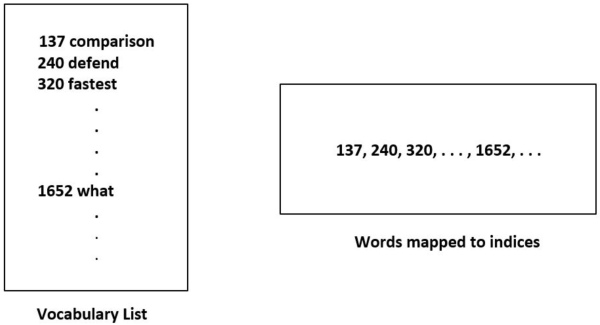
Each word in the e-mail is then mapped to the number in the vocabulary list. For example, if the word “what” appears in the list, it is mapped to the number “1652”. This is done using Python dictionary. First, vocabList.txt – the file which has the words along with numbers – is converted to Python dictionary. Each word in the e-mail is then mapped to the number in the vocabulary list. For example, if the word “what” appears in the list, it is mapped to the number “1652”.
vocabDictionary = {}
with open("vocab.txt") as f:
for line in f:
(key, val) = line.split()
vocabDictionary[int(key)] = val
The dictionary is then used to map the words to the index number using this code snippet –
indices = [];
for key,value in vocabDictionary.items():
for each_word in stemmed:
if each_word==value:
indices.append(key)
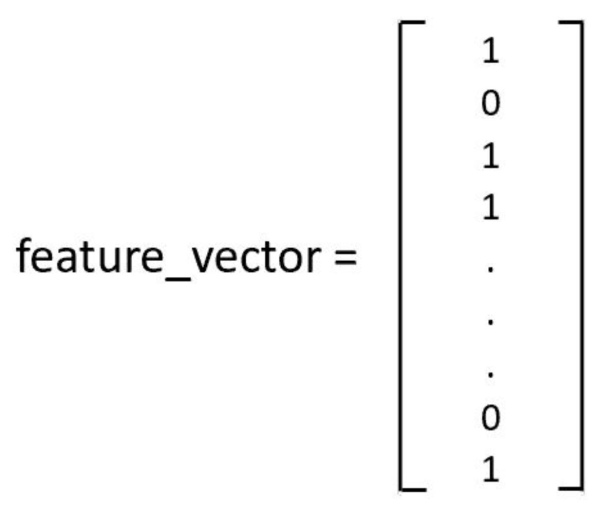
After mapping the words to indices, a feature vector is created using these indices. The feature vector is a binary feature vector that indicates whether a particular word occurs in the e-mail. If word ‘k' is present in e-mail, then feature_vector(k) = 1. An example of binary feature vector is shown below:
Training SVM
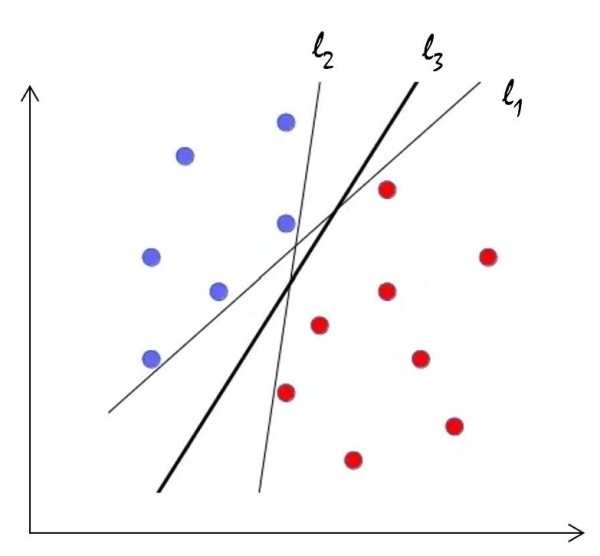
Support Vector Machine is a supervised machine learning algorithm used mostly for classification problems. When a Support Vector Machine is explicitly told to find a line or hyperplane which best segregates features into 2 classes, it does so by arriving at a line that is at a maximum distance from each of the points that “support” the vector. In the figure shown below, the line l3 has the highest “margin” i.e. the distance between the line and the closest point of either class. Hence this is the optimal line that separates the two classes.
We implemented SVM using python package and achieved train accuracy of 99.97%. The RPi takes less than 30 seconds to train the SVM.
from sklearn import svm
clf = svm.SVC(kernel='linear', C = 1.0)
clf.fit(X_train,y_train.ravel())
The steps involved in Design and testing are illustrated in the figure below:
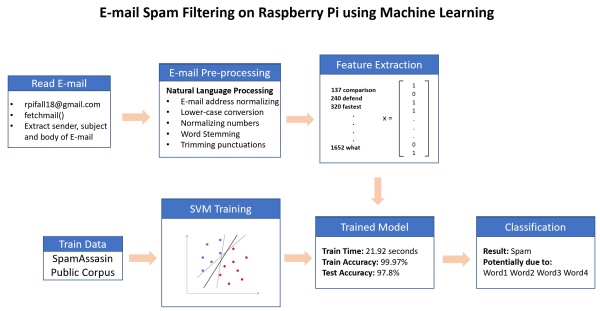
Testing
After training SVM, we tested the system using test vectors. The model achieved test accuracy of 97.8%
import scipy.io as sio
#load Spam Test Data
mat_contents = sio.loadmat('testvector.mat')
X_test=mat_contents['Xtest']
y_test=mat_contents['ytest']
#test data prediction
y_pred_test=clf.predict(X_test)
#calculate test accuracy
count=0.0
for i in range(len(y_test)):
if(y_pred_test[i]==y_test[i]):
count=count+1
accuracy = count/len(y_test)*100
print("Test Accuracy:" + str(accuracy))
We also tested the performance of the spam classifier on many e-mails. Two examples, one for spam and one for non spam e-mails are shown below –
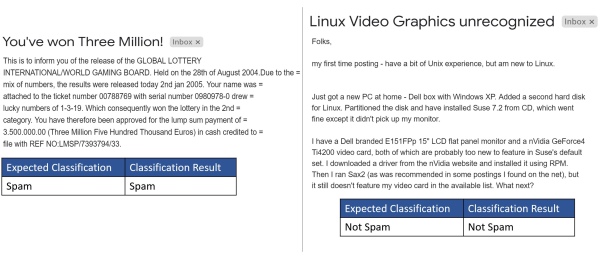
Issues encountered and their resolution
We discuss here the issues we encountered and how we resolved them.
Fetching e-mail on Raspberry Pi using imaplib: We tried to use imaplib to fetch e-mails on the RPi. But gmail refused to provide access. So we switched to the fetchmail method outlined above.
Running shell commands as non-root inside sudo python script call: To get the display running on piTFT, we have to execute python code using ‘sudo’. But fetchmail, the email client that we used to receive e-mails, does not run as ‘root’. We spent several hours trying to figure out how to run a linux shell command as non-root when python script is called using sudo. We resolved the issue of running commands as non-root by executing ‘su – pi -c’ which runs a command in the shell as the user pi, instead of root.
Incorrect classification of very short e-mails: The model that we trained is not robust enough for very short e-mails. Sometimes, very short non-spam e-mails are classified as spam. This is a limitation of the current implementation and we are working on resolving this by exploring other SVM kernels.
Results
Results of this project are as expected. When we started off with the initial plan, the goal was to build a stand-alone E-mail spam filter on Raspberry Pi using Machine Learning. We successfully implemented the goals we had in mind and also identified the shortcomings/limitations of our system as we progressed through different stages of the project. We were able to achieve a really good training accuracy and also a decent test accuracy. We tested the system on 6 e-mail samples – 4 of them being spam and 2 being non-spam. Our system was able to correctly classify all the six examples. In this project, we also implemented the User Interface to provide useful information to the user when training and testing the spam filter. Overall, we met all the goals and also completed all tasks on time. We kept track of our project using the timeline we prepared at the beginning of the project, shown below –
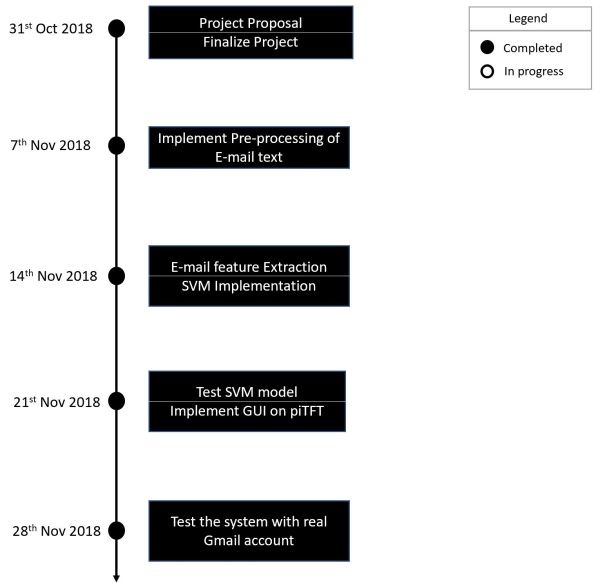
The figure shown below summarizes the results.

The User Interface implemented for this project is shown below:

Source: E-mail Spam Filtering on Raspberry Pi using Machine Learning