
Have you ever written some software that, despite your best coding efforts, didn’t run as fast as desired? I have, writes David C. Black, Senior Member of Technical Staff at Doulos.
Have you thought, “If only there were an easy way to put some of the code into multiple custom processors or custom hardware that wasn’t so expensive”?
After all, your application is one of many, and custom hardware takes time and money to create. Or does it?
I began rethinking this proposition recently when I heard about the Xilinx high-level synthesis tool, Vivado HLS.
In combination with the Zynq-7000 All Programmable SoC, which combines a dual-core ARM Cortex-A9 processor with an FPGA fabric, high-level synthesis opens up new possibilities in design.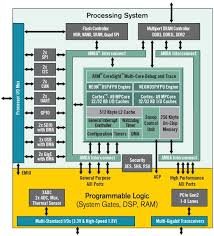
This class of tools creates tuned RTL from C, C++ or SystemC source code. Many purveyors of this technology exist, and the rate of adoption has been increasing in recent years.
So, how hard would it be to migrate some of that slow code into hardware, if indeed I could simply use Vivado HLS to do the more demanding computations?
After all, I usually wrote my code in C++, and Vivado HLS used C/C++ as an input. The ARM processor cores meant I could run the bulk of my software in a conventional environment.
As I started to think about this transformation from a software perspective, I grew concerned about the software interface.
After all, HLS creates hardware dedicated to processing hardware interfaces. I needed something easy to access, like a coprocessor or hardware accelerator, to make the software go faster.
Also, I didn’t want to write a new compiler. To make it easy to exchange data with the rest of the software, the interface needed to look like simple memory locations where we could place the inputs and later read back the results.
Then I made a discovery. Vivado HLS supports the idea of creating an AXI slave with relatively little effort. This capability started me thinking an accelerator might not be so difficult to create after all. Thus, I found myself coding up a simple example to explore the possibilities. I was pleasantly surprised with how it turned out.
Let’s take a walk through the approach I took and consider the results.
For my example, I chose to model a set of simple matrix operations such as add and multiply. I didn’t want it to be constrained to a fixed size, so I would have to provide both the input arrays and their respective sizes.
An ideal interface would put all the values as simple arguments to a function. The interface to the hardware would need to have a simple way to map the function arguments to memory locations.
For example, the registers would hold information about how matrices were laid out and what the desired operations would be.
The command register would indicate which operation to do. This would allow me to combine several simple operations into one piece of hardware. The status register would simply be a way to know if the operation was in progress or had finished successfully. Ideally, the device would also support an interrupt.
Going back to the hardware design, I learned that Vivado HLS allows for array arguments to specify small memories.
Assuming the ability to synthesize the AXI slave, how would this fit with the software? My normal coding environment assumes Linux.
For more detail: How to make slow software run quicker