
The navigation methods currently employed by many autonomous vehicle companies such as
Google, Uber, and Telsa rely upon manually driving roadways and gathering information about
the roadway infrastructure with lidar before any autonomous navigation is possible. While this
method can be very effective, issues can arise when the roadway undergoes changes such as during
construction or road closure. Additionally, mapping all of the over 400 million miles of roadway
in the United States is impractical. A navigation method which does not require the route to be
mapped prior to driving could allow an autonomous vehicle to navigate virtually anywhere.
1.1 Thesis Motivation
Previous work in this unmapped navigation method is presented in [1]. In this work, a smallscale remote-controlled (RC) vehicle navigated around a single turn using only the computer-vision
feedback from an Xbox Kinect. The algorithm used to control the vehicle relied on identifying
all pixels in a given frame that were yellow or red, identifying which of those pixels were lane
markers, and then estimating a steering point from the identified pixels. The largest drawbacks to
this algorithm were the large bottlenecks that occurred from scanning the entire image for red and
yellow pixels, and then identifying which of these pixels were adjacent to tile-colored pixels so
that the lane lines could be isolated. As such, the time step for each frame was approximately 200
ms, or 5 fps. One of the primary motivations for this thesis is to build upon the previous method of
using color for lane marker detection, but create a more efficient algorithm that would allow for a
greatly improved frame rate.
A secondary motivation for this thesis is to improve the success rate of object identification
while the vehicle was in motion. While the work presented in [1] attempted to identify pedestrians
using open-source skeleton tracking libraries from Microsoft, the algorithm had a 40% failure rate.
Because autonomous vehicles need to demonstrate almost perfect reliability in order to become
commercially viable, this thesis seeks to successfully demonstrate a machine-learning algorithm
for the identification of street signs with near 0% failure rate.
1.2 Design Objective
With this motivation in mind, the objective of this thesis is to design an autonomous ground vehicle capable of successfully navigating a closed course, while adjusting speed using only computervision. In other words, the vehicle must:
- identify common traffic control signs and adjust the speed of the vehicle accordingly, and
- determine lane boundaries and navigate the vehicle as close to the center of the lane as
possible without prior mapping.
1.3 Autonomous Vehicles
Primitive versions of autonomous vehicles have existed since at least the 1950s [2], but the first
real advances in autonomous vehicle technology occurred in the 1980s. Carnegie Mellon developed an autonomous vehicle in a neural network that forms the foundation many modern control
methods are built upon [3]. In the development since the 1980s, a stratification of autonomous vehicle capabilities has emerged. While currently almost all commercial passenger vehicles require
driver intervention 100% of the time, more car manufacturers and technology firms are developing
vehicles that have increased autonomy.
1.3.1 Levels of Autonomy
As defined by the Society of Automotive Engineers in [4], there are six levels of vehicle automation ranging from “No Automation” to “Full Automation”. The first three levels are defined
by human drivers monitoring the driving environment. Level-0 means that the driver controls
steering and speed completely, even if they might be receiving feedback from the car. An example
would be the lane departure warnings or backup camera sensors seen in many currently produced
vehicles. Level-1 is defined by the vehicle having control of either steering or vehicle speed, but
not both. Cars that have adaptive cruise control while the driver continues steering or parking
assistance while the driver controls speed are examples of level-1 vehicles. Level-2 vehicles take
care of both driving and steering tasks, but the driver must still have hands on the wheel and feet
on the pedals to be ready at any moment should the system fail.
In level-3 vehicles and above, the driver can begin to have some level of inattention to the
roadway safely. Level-3 vehicles are programmed to be able to respond to immediate threats like
collisions and obstacles, but still might request driver intervention within a specified time period.
Therefore, drivers are still expected to remain awake in a level-3 vehicle. At level-4, the vehicle
can respond to any hazard completely autonomously. It might request that a human driver take
control, but even if the driver does not intervene, the vehicle can guide itself to safety. Level-5 vehicles have no human intervention whatsoever. An example would be an automated taxi or delivery
vehicle between two known points so that no driver is necessary. In order to successfully navigate
the dynamic environment the roadway presents, current autonomous vehicles must be capable of
handling a number of tasks outlined below.
1.3.2 Lane Keeping
According to [5], 22% of vehicles ran off the edge of a roadway, and 11% of vehicles failed
to stay in the proper lane in 5,471 crashes studied from 2005 to 2007. Many current vehicles
are equipped with lane departure warning systems which can alert the driver whenever they have
drifted out of their lane [6], [7]. In the case that the driver begins to unexpectedly drift from the
lane, such systems will respond with a loud beep and a vibration of the driver seat or steering
wheel to warn the driver. The systems appear to be helping prevent accidents. From [8], lane
departure warning lowers the rates of single-vehicle, sideswipe and head-on crashes by 11%, and
the rate of injury that the crashes cause by 21%. The reduction in accidents from these level-0
driver-assistance technologies offers the hope that future autonomous vehicles with even greater
control over the steering and navigation can reduce these accidents even further.
1.3.3 Speed Control
Some vehicles on the road currently posses the level-1 technology of adaptive cruise control.
Like typical cruise control, this technology allows for a vehicle to maintain a speed as set by the
driver, but is unique in that the vehicle will adjust the speed as necessary by traffic conditions
[9]. These systems employ a radar or lidar to continually search for upcoming vehicles. When
a vehicle is detected, the car will slow and match the speed of the leading vehicle to maintain
a safe driving distance. If the path is cleared, the vehicle will then accelerate back to the set
speed. Another example of speed control in autonomous vehicles is automatic braking for collision
avoidance [10]. When the autonomous vehicle detects an oncoming vehicle from the side or a fast
approaching vehicle from the front, the brakes are immediately applied to reduce the severity of
the accident or avoid the accident entirely.
1.3.4 Object Recognition
While lane keeping and speed control can be accomplished by level-0 and level-1 vehicles
that are currently on the road commercially, level-2 and above vehicles require an even greater
awareness of the surrounding environment to function with no driver intervention at all. At this
point, object recognition becomes necessary. Of particular importance, vehicles must be able to
detect and avoid pedestrians in urban environments [11]. Additionally, vehicles must be able to
recognize traffic control signals such as stop signs, speed limit signs, yield signs, and traffic lights
to properly follow traffic laws [12].
1.4 Machine-Learning and Computer-Vision Algorithms
To perform the necessary driving functions, an autonomous vehicle must have a well-trained
computer to coordinate the numerous sensors and cameras and respond immediately to potential
obstacles and collisions. Machine-learning and computer-vision algorithms like those discussed
below will be necessary to teach the computer how to react to these dynamic environments.
1.4.1 Support Vector Machines
For this thesis, the machine-learning algorithm utilized is a support vector machine (SVM).
SVMs are a type of supervised learning, meaning that training data are first labeled and classified
by a human before they are given to the computer. Supervised-learning algorithms then use those
labeled data as the basis for deciding whether subsequent unlabeled data belong to one class or
another.
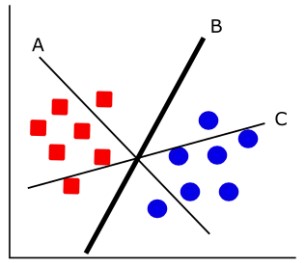
SVMs work by creating a hyperplane, or decision boundary, among the sets of labeled training
data supplied by the user. The first priority in selecting the hyperplane is that all of the data from
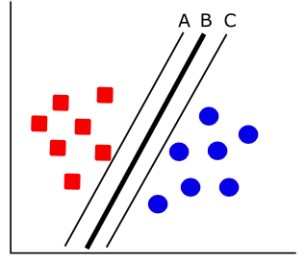
one class falls on the same side of the decision boundary, as shown in Figure 1.1. The second
priority is to maximize the distance from the closest training data points on either side of the
hyperplane, as seen in Figure 1.2 [13]. The measure of how far the hyperplane lies from the closest
training data is known as the margin.
SVMs are commonly used in computer-vision applications for object detection. In this case,
the two classes would be comprised of positive training data from images with the object, and
negative training data from images without the object. Once the hyperplane has been created from
this training data, subsequent images can be identified as containing or not containing the particular
object based upon which side of the hyperplane the new image falls.
1.4.2 Histogram of Oriented Gradients
In order for the SVM to create a hyperplane, the images of the object to be detected must be
transformed into a numerical form that the algorithm can understand. This transformation results in
what is known as a feature vector, and the algorithms that perform these transformations are called
feature descriptors. The feature descriptor used in this thesis is the histogram of oriented gradients
(HOG). HOG has already been utilized in autonomous vehicle applications for the identification
of pedestrians [14], bicyclists [15], and other vehicles [16].
The use of HOG as a feature descriptor became widespread after its usage in [14] for the
detection of pedestrians. As the name implies, the image features described by HOG are the
directionality of image gradients and how these gradient directions are distributed. The first step in
finding the HOG descriptor is to calculate these gradients. Dalal and Triggs [14] use several kernels
for calculating the image gradient, but found most success with 1-D centered point derivatives of
the form [
−1 0 1]
for the horizontal gradient gx and [
−1 0 1]T
for the vertical gradient gx.
This means that the gradient of a pixel in the image is calculated by comparing the darkness of
the pixels on the left and right to one another, and then repeating for the top and bottom pixels, as
shown in Figure 1.3. In this example, the pixels on the bottom-right are darker than the pixels in
the top-left. Using the gradient calculation above, the horizontal and vertical gradients are given
by
∇f(x, y) =
gx
gy
=
f(x + 1, y) − f(x − 1, y)
f(x, y + 1) − f(x, y − 1)
(1.1)
For the given example, both the horizontal and vertical gradient are then calculated as
gx
gy
=
f(x + 1, y) − f(x − 1, y)
f(x, y + 1) − f(x, y − 1)
=
100
100
(1.2)
The gradient magnitude and orientation can then be found by:
g =
√
g
2
x + g
2
y =
√
1002 + 1002 = 100√
2 (1.3)
θ = tan−1
(
gy
gx
) = tan−1
(
100
100
) = 45◦
(1.4)
This indicates that the gradient from light to dark is oriented down and to the right at a 45◦
angle
from the pixel being examined. The angle of θ is typically made to be unsigned and limited to
between 0◦
and 180◦
for simple objects, although [14] notes that signed orientations may be necessary for more complicated object recognition tasks. The gradient calculation is then performed
for every pixel in the image.
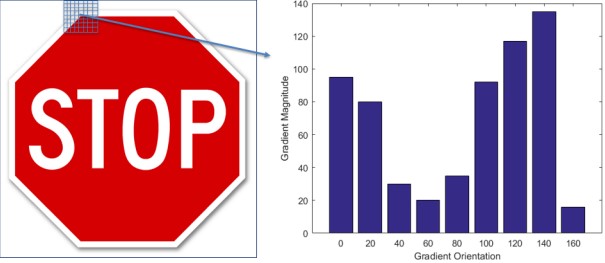
With the image gradient calculated, the image is divided into boxes of pixels called cells. The
number of pixels per cell can be increased or decreased depending on how fine the details of the
image are, but for this example the cell size will be assumed to be 8×8 pixels. The trade-off of
capturing more detail in the image is the increased computation time needed to process the image.
Within these cells, the gradients are sorted into one of 9 bins corresponding to the angles 0, 20,
40,…, 160◦
. If the gradient orientation falls exactly on one of the bins, for example at 120◦
, the
full value of the gradient magnitude would be added to that bin. If the gradient orientation falls
between bins, the value of the gradient magnitude is split proportionally between the nearest bins.
For example, at 90◦
the value of the gradient would be split equally between the 80◦
and 100◦ bins.
An example of splitting the gradient orientations into a histogram is shown below in Figure 1.4.
Once histograms have been calculated for all 8×8 pixel cells, the histograms must be normalized to account for differences in lighting. Otherwise, histograms from particularly light or dark
areas of the image would have gradients with relatively high or low magnitudes. To normalize the
histograms, the 8×8 pixel cells are grouped into larger blocks of 16×16 pixels. Since there are
4 cells of 8×8 pixels in each 16×16 pixel block, and each cell contains 9 values representing the
gradient magnitudes at each bin orientation, the entire block can be represented by a 36×1 vector.
The values within the vector are normalized by dividing each element by the L2 norm of the entire
vector. The L2 norm has the form
|x| =
√
x
2
1 + x
2
2 + …x2
n
where x1, x2, …, xn are the elements of the vector being normalized. Once the vector has been
normalized, the block is shifted over by 8 pixels so that there is overlap with the previous block.
The normalization is conducted again, and the cycle of shifting and normalizing is repeated until
the end of the row. The block then shifts downwards 8 pixels and the process repeats until the
entire image has been normalized. This process is known as sliding-window normalization, and is
shown in Figure 1.5.

When the 8×8 pixel blocks from the original image are replaced with the strongest normalized
oriented gradients from that particular box, the resulting image shows the general contour of the
object being studied. An example of the normalized gradient field image is shown in Figure 1.6.
With all blocks normalized, the final feature vector which represents all information about the
image is created by concatenating the 36×1 vectors from each block. If the size of the image
being analyzed was 64×64 pixels, there would be 7 blocks in the horizontal direction and 7 in the
vertical direction. With 36 elements in each block, the total vector representing the entire image
would be 1,764 elements long for an input image vector of size 12,288 (64×64×3). This 1,764
element feature vector is used by the SVM for deciding whether subsequent images passed to the
program have sufficiently similar feature vectors to be considered the same object.

1.4.3 Color Modeling
In many computer imaging tasks, a user may wish to detect a certain colored object. From a
given input image, the computer will examine each pixel and determine whether the pixel color
properties fall within certain thresholds. The rejection or retention of pixels based on these color
properties is known as color masking. For example, a red color mask of a stop sign would appear
as shown in.
In order to perform color masking, there must be a method to determine which pixels from
an image qualify as falling within the threshold of the color being sought. A common method of
classifying pixel colors is using the red-green-blue (RGB) model, wherein a pixel is classified by
its combination of red, green, and blue light colors. As can been seen in Figure 1.8, colors like
magenta, cyan, and yellow can be created from combinations of the primary three colors. The
limitation with this model is that it is not robust to changes in lighting conditions, so the same
object will have drastically different red, green, and blue values in shadow and bright light.