Faster than real-time! Based on Mozilla’s DeepSpeech Engine 0.9.*

UPDATE June 2020: Revised instructions for DeepSpeech version 0.7.*, except Raspberry Pi 4 screenshots which remained unchanged. The benchmark table has remained the same, as I didn’t observe any improvement in inference speed. However, there appears to have been a precision enhancement – the audio file 2830-3980-0043.wav, previously transcribed as “experience proofless”, is now transcribed as “experience proves this”, making it more coherent. The article can still be accessed on Steemit in its archived form. I recently added a hot word script to mic_stream
In this article we’re going to run and benchmark Mozilla’s DeepSpeech ASR (automatic speech recognition) engine on different platforms, such as Raspberry Pi 4(1 GB), Nvidia Jetson Nano, Windows PC and Linux PC.
2019, last year, was the year when Edge AI became mainstream. Multiple companies have released boards and chips for fast inference on the edge and a plethora of optimization frameworks and models have appeared. Up to date, in my articles and videos I mostly focused my attention on the use of machine learning for computer vision, but I was always interested in running deep learning based ASR project on an embedded device. The problem until recently was the lack of simple, fast and accurate engine for that task. When I was researching this topic about a year ago, the few choices for when you had to run ASR (not just hot-word detection, but large vocabulary transcription) on, say, Raspberry Pi 3 were:
- CMUSphinx
- Kaldi
- Jasper
Links:
Python 3 Artificial Intelligence: Offline STT and TTS
The Best Voice Recognition Software for Raspberry Pi
And a few more. Setting up any of them was not simple and they were not ideal for use in environments with limited resources. A couple of weeks ago, I revisited this topic and discovered Mozilla’s DeepSpeech engine through some investigation. It has been in existence for some time, but only in December 2019 did they unveil a 0.6.0 version of their ASR engine, featuring a tflite model and other notable enhancements. The English model’s size has been decreased from 188 MB to 47 MB. Reuben Morais from Mozilla stated in the news release that DeepSpeech v0.6 utilizing TensorFlow Lite operates at a speed quicker than real-time on a singular core of a Raspberry Pi 4. I chose to test the validity of that statement by conducting benchmark tests on various devices and developing my audio transcription software with hot word detection. Let’s find out what the outcome is.
Hint: I wasn’t disappointed.
Installation
Raspberry Pi 4/3B
The pre-built wheel package for arm7 architecture is set to use.tflite model by default and installing it as easy as just
pip3 install deepspeechThis is it really! The package is self-contained, no Tensorflow installation needed. The only external dependency is Numpy. You’ll need to download model separately, we’ll cover it in the next section.
Nvidia Jetson Nano
The latest version of DeepSpeech, 0.7.3 has pre-built binaries for aarch64 architecture, which have model type by default set to .tflite. Unfortunately, the wheel is only available for python 3.7 and NVIDIA’s latest Jetpack 4.4 still comes with Python 3.6.9 as default python3… I don’t know why and neither do the maintainers of DeepSpeech. Which means we’ll have to install Python3.7 first, then install a couple of more dependencies and only then install DeepSpeech.
sudo apt-get install python3.7 python3.7-dev
python3.7 -m pip install cython
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.7.3/deepspeech-0.7.3-cp37-cp37m-linux_aarch64.whl
python3.7 -m pip install deepspeech-0.7.3-cp37-cp37m-linux_aarch64.whlWindows 10/Linux
For Windows and Linux you’ll need to download .tflite enabled version of pip package.
pip3 install deepspeech-tfliteIf you’re using Python 3.8 you’ll likely to encounter DLL loading error on Windows. It can be corrected fairly simple with a little change to DeepSpeech package code, but I suggest you just install the version for Python 3.7, which works flawlessly.
If you have NVIDIA GPU and CUDA 10 installed you can opt for GPU-enabled version of Deepspeech
pip3 install deepspeech-gpuBenchmarking
Let’s download the models, language model binary and some audio samples. Tflite model is used for inference on CPU/embedded platforms, .pbmm is a memory mapped larger model – only download that one if you want to run inference with deepspeech-gpu package. Scorer is the language model and while not necessary to run inference, having language model significantly improves accuracy as opposed to just relying on acoustic model – I talk in more details about DeepSpeech architecture in the accompanying video, make sure to check it out!
curl -LO https://github.com/mozilla/STT/releases/download/v0.7.1/deepspeech-0.7.1-models.tflite
curl -LO https://github.com/mozilla/STT/releases/download/v0.7.1/deepspeech-0.7.1-models.pbmm
curl -LO https://github.com/mozilla/STT/releases/download/v0.7.1/deepspeech-0.7.1-models.scorerDownload example audio files
curl -LO https://github.com/mozilla/STT/releases/download/v0.7.1/audio-0.7.1.tar.gz
tar xvf audio-0.7.1.tar.gzRaspberry Pi 4 run:
deepspeech --model deepspeech-0.7.*-models.tflite --scorer deepspeech-0.7.*-models.scorer --audio audio/2830-3980-0043.wavIf successful you should see the following output
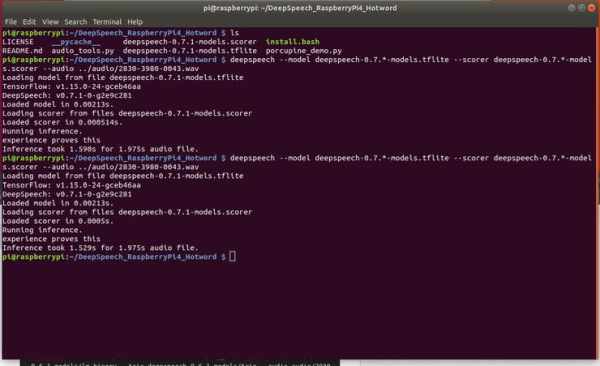
Not bad! 1.529 seconds for 1.975 seconds sound file. It IS faster than real time.
Nvidia Jetson Nano run:
deepspeech --model deepspeech-0.7.*-models.tflite --scorer deepspeech-0.7.*-models.scorer --audio audio/2830-3980-0043.wavHm.. a little bit slower than Raspberry Pi. That is expected, since Nvidia Jetson CPU is less powerful than Raspberry Pi 4. There are no pre-built binaries for arm64 architecture with GPU support as of this moment, so we cannot take advantage of Nvidia Jetson Nano’s GPU for inference acceleration. I don’t think this task is on DeepSpeech team roadmap, so in the near future I’ll do some research here myself and will try to compile that binary to see what speed gains can be achieved from using GPU. But seconds is still pretty decent speed and depending on your project you might want to choose to run DeepSpeech on CPU and have GPU for other deep learning tasks.
Windows 10/Linux
deepspeech --model deepspeech-0.7.*-models.tflite --scorer deepspeech-0.7.*-models.scorer --audio audio/2830-3980-0043.wav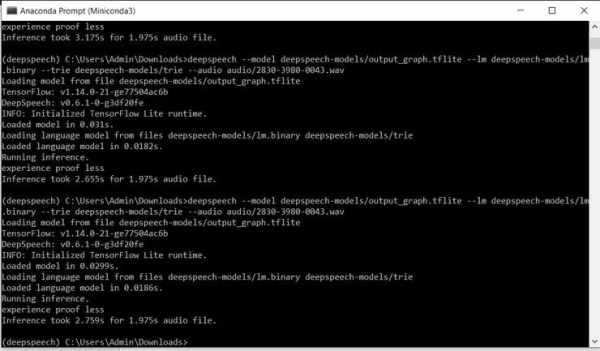
Source: Offline Speech Recognition on Raspberry Pi 4 with Respeaker