
1. Introduction
“Big data analysis has become increasingly indispensable across various scientific and engineering fields. However, dealing with the sheer volume of data often results in slow processing times due to computationally intensive algorithms, such as the 3-D Fourier transform or 3-D prestack migration in geophysics (Yilmaz, 2001). Another challenge arises when the data set surpasses the available RAM (random access memory) in a computing system. In such cases, the data needs to be divided into smaller subsets and processed separately, leading to even longer processing times. With data sets continually growing and Moore's Law reaching its limits (Kumar, 2015), traditional sequential algorithms are proving inefficient for handling cutting-edge data analysis tasks.
A plausible solution to enhance the efficiency of seismic processing is the development of parallel and distributed algorithms, such as the distributed-memory Fast Fourier Transform (Gholami et. al., 2016) or parallel Reverse Time Migration (Araya-Polo et. al., 2011). As parallel and distributed computing are gaining prominence, the demand for studying and implementing these methods is also increasing. In our project, we constructed a distributed computing system using 4 Raspberry Pis and evaluated its performance using straightforward parallel and distributed algorithms.”
2. Background information
This section will explain the concepts of parallel computing, distributed computing, and Raspberry Pi.
2.1. Parallel Computing
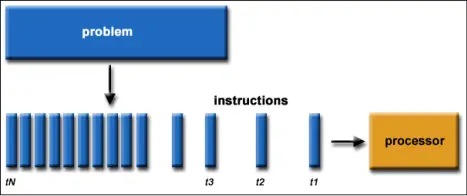
In the conventional approach, algorithms are executed sequentially, as depicted in Figure 1:
– The problem is divided into a set of distinct instructions.
– These instructions are executed one after the other in a linear manner.
– The entire process occurs on a single processor.
– At any given moment, only one instruction is executed.
Parallel computing involves the utilization of multiple computing resources to address a computational problem simultaneously (Figure 2):
– The problem is divided into distinct parts that can be solved concurrently.
– Each part is further subdivided into a series of instructions.
– Instructions from each part execute simultaneously on separate processors.
– An overarching control/coordination mechanism is employed to manage the parallel execution effectively.
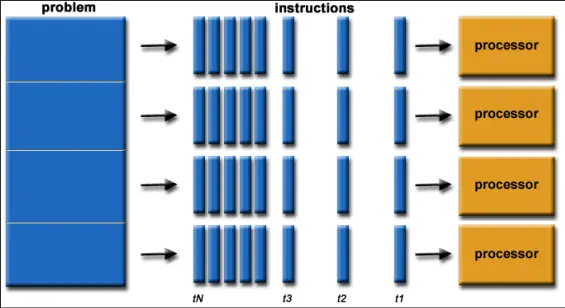
By partitioning a task into X subtasks and executing them concurrently, the execution speed can be enhanced by a factor of X.
2.2. Distributed Computing
A distributed computing system is a hardware-software combination consisting of components that are located on different networked computers and communicate and coordinate actions among each other through passing messages. The components interact with one another in order to achieve common goals/tasks (Steen & Tanenbaum, 2017). A common distributed architecture is demonstrated in Figure 3:
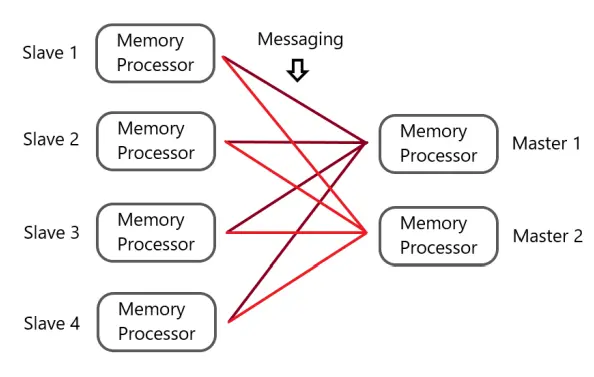
In a distributed system, every node is equipped with both a memory component (RAM) and a processor component (CPU). The master nodes take charge of distributing and managing data and tasks across the entire system, while the slave nodes execute the assigned tasks, following the instructions from the master. The fundamental aim of a distributed system is to leverage the collective memory and processing capabilities of diverse computers to efficiently solve computational problems while maintaining fault tolerance. This means that even if a few nodes encounter issues or fail, the system will continue to operate smoothly and reliably.
2.3. Raspberry Pi
A Raspberry Pi (RPi) is a compact and affordable single-board computer, roughly the size of a credit card. It has the capability to run Linux and other lightweight operating systems, which are designed to be compatible with ARM processors. The ARM processor is a type of multi-core CPU based on the RISC (reduced instruction set computer) architecture, which was developed by Advanced RISC Machines (ARM). A detailed overview of the components of the RPi 3 Model B+ can be found in Figure 4.

In this project, RPis are employed, featuring 1GB of RAM and a quad-core CPU running at 1.4GHz, integrated onto a sturdy motherboard. Each RPi seamlessly aligns with another, simplifying the process of scaling up by merely adding more RPi units. Following a careful evaluation of other alternatives, such as Qualcomm DragonBoard and ASUS Tinker Board, we concluded that the RPi was the ideal selection for this project due to its favorable attributes in terms of cost-effectiveness, functionality, portability, and scalability.
3. Building the system
3.1. Components and Costs
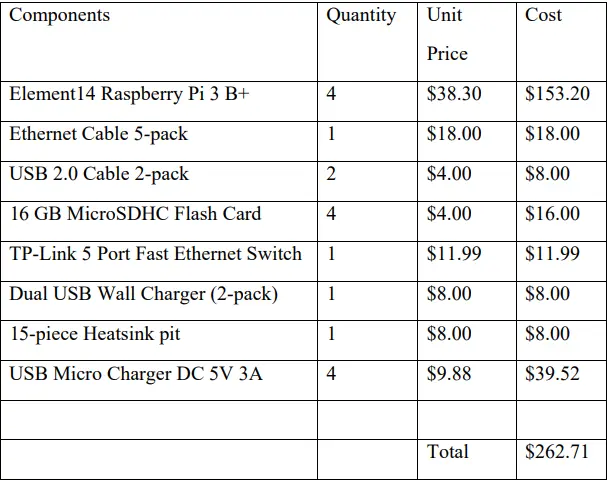
The entire project incurs a cost of $262.71, as outlined in Table 1. Fortunately, we could utilize an existing monitor with an HDMI-VGA cable, along with a keyboard and mouse available in the lab room, eliminating the need for additional expenses on these components.
3.2. General Architecture
The primary components essential for constructing a computing cluster include:
– Computer hardware
– Operating System (OS)
– An MPI (Message Passing Interface) library
– An Ethernet switch
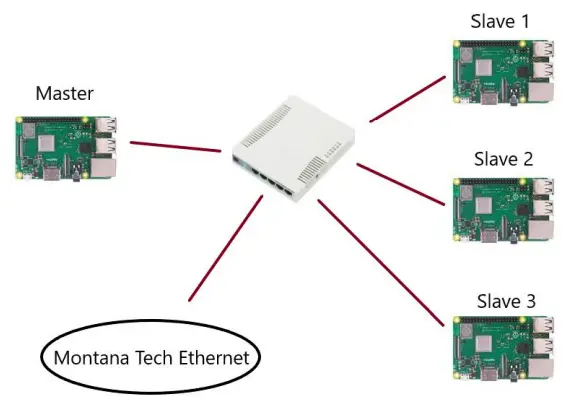
The main network architecture is illustrated in Figure 5. The system design incorporates 4 RPi nodes, a 5-port Ethernet switch, Raspbian OS, and MPICH with Python wrapper (MPI4PY). The RPis were connected to the Montana Tech network via the Ethernet switch.
3.3. Operating System
In this project, we evaluated two distinct operating systems for the Raspberry Pi: Raspbian and Arch Linux ARM. Raspbian is a Debian-based OS specifically optimized for the RPi, and it comes with a complete desktop environment and an extensive collection of precompiled packages. Due to these advantages, Raspbian is an excellent choice for beginners starting with the RPi and Linux. However, one drawback of using Raspbian is that it contains numerous unnecessary packages, leading to slower installation and start-up times.
However, Raspbian adopts a fully-featured approach, while Arch Linux ARM follows a minimalist approach. By default, Arch Linux provides a bare-bone, minimal environment that boots swiftly (within 10 seconds) to a command line interface (CLI) with network support. Arch Linux allows users to start with a clean and rapid setup, installing only the necessary packages as needed, thereby optimizing the system for specific purposes, such as data processing or system administration. Nevertheless, using Arch Linux entails a steeper learning curve, especially for new users, as they must manually install many packages and their dependencies using an unfamiliar CLI.
Considering that the main objective of this project is to explore RPi, Linux, parallel, and distributed computing, Raspbian was chosen as the OS for our system. It offers a user-friendly environment and pre-installed packages that facilitate seamless exploration. However, for users well-versed in the Linux operating system and seeking more control over their setup, Arch Linux may be a viable alternative worth considering.
3.4. MPI and programming language
MPICH serves as a high-performance and widely portable implementation of the MPI standard. The decision to opt for MPICH was influenced by its support for both synchronous and asynchronous message passing. Additionally, the installation process of MPICH and its Python wrapper (mpi4py) on the RPi is swift and straightforward. For MPICH to function correctly, it necessitates password-less Secure Shell (SSH) access between all nodes. This was achieved by generating a set of public-private keys for each node and then distributing the public keys of all nodes into each node's list of authorized keys.
Python was a natural choice for the programming language in this project due to its widespread usage in the scientific computing realm and our own familiarity with it. Python is particularly well-suited for rapid prototyping, thanks to its concise syntax and being an interpreted and dynamically typed language. While Python does exhibit certain performance tradeoffs, such as lack of type safety and comparatively slower execution time, it proved to be adequate for the purposes of this project.
4. Testing the system
After constructing the system, our next step involved testing its fundamental functionality using a basic MPI program. Following that, we conducted a Monte Carlo simulation using three different methods: sequential, parallel, and distributed. Our objective was to compare the performances of these methods to assess their relative efficiencies.
4.1. Functionality testing
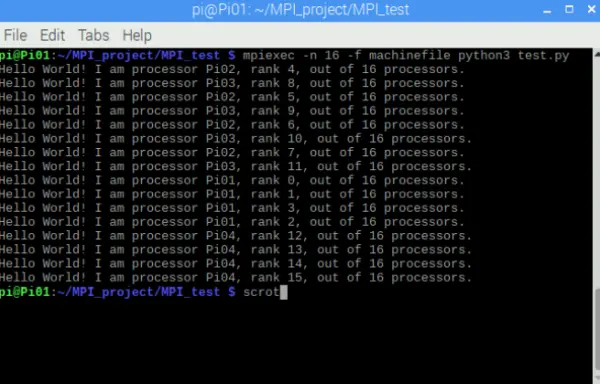
A straightforward Python test script containing a “hello world” message was transmitted via MPI from the master node to the slave nodes. The task involved all 16 processors on the network sending a confirmation back to the master node, validating that each processor was functioning correctly (Figure 6).
4.2. Monte Carlo approximation of Pi
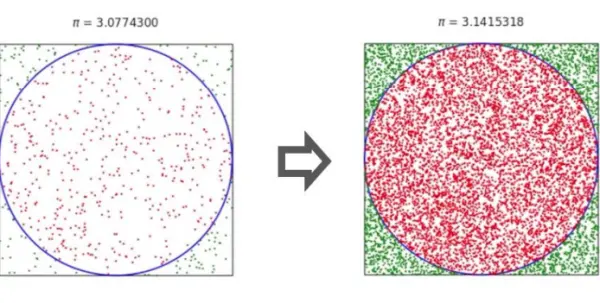
Monte Carlo methods encompass a diverse range of computational algorithms that heavily rely on repeated random sampling to derive numerical results. The fundamental concept behind Monte Carlo methods is that randomness can be effectively employed to address problems that might otherwise possess a deterministic nature. In this project, we utilized a Monte Carlo algorithm specifically for approximating the value of π (Figure 7).
The procedure involves the following steps:
1. Generate a random point within the confines of the unit square.
2. Determine whether the generated point falls within the circle inscribed within the unit square, and record the outcome.
3. Repeat steps 1 and 2 a total of N times.
4. Count the number of points that fall within the circle enclosed by the unit square (n).
5. Calculate the value of Pi using the formula:
This algorithm is highly amenable to parallelization because each point generated is entirely independent of every other point.
4.2.1. Parallel Processing on a single RPi
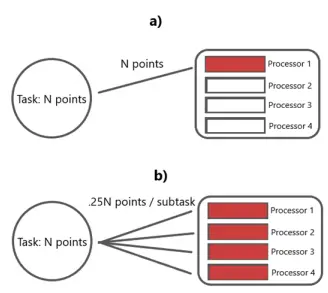
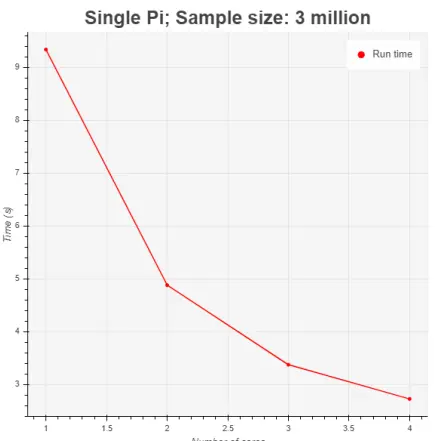
The second phase of testing involved conducting a Monte Carlo simulation. Initially, we executed the Monte Carlo algorithm with a sample size of 3 million in a sequential manner, implying that only one processor was engaged in performing the task. Subsequently, we employed the Python multiprocessing library to parallelize the task into 2, 3, and 4 subtasks, with each subtask executed on separate processors (or cores) within a single node (Figure 8). Throughout this process, the sample size remained 3 million.
Before conducting the experiment, we anticipated that parallelization would significantly decrease the run time of the Monte Carlo algorithm, as the computational burden would be distributed among multiple processors instead of relying on a single processor. The obtained results (Figure 9) verified this expectation. It was evident that there was a nearly linear improvement in run time as the number of cores involved in sharing the workload increased.
4.2.2. Parallel vs Distributed Computing
Following the analysis of runtimes for both sequential and parallel algorithms on a single node, our focus shifted to investigating the distribution of tasks and data across the network. Initially, we aimed to evaluate the impact of converting the data into TCP/IP format and transmitting them between nodes in the network. Subsequently, we distributed the task to all 16 nodes within the network to showcase the advantages of harnessing all available computing resources.
4.2.2.1. 4 cores: single node vs four nodes
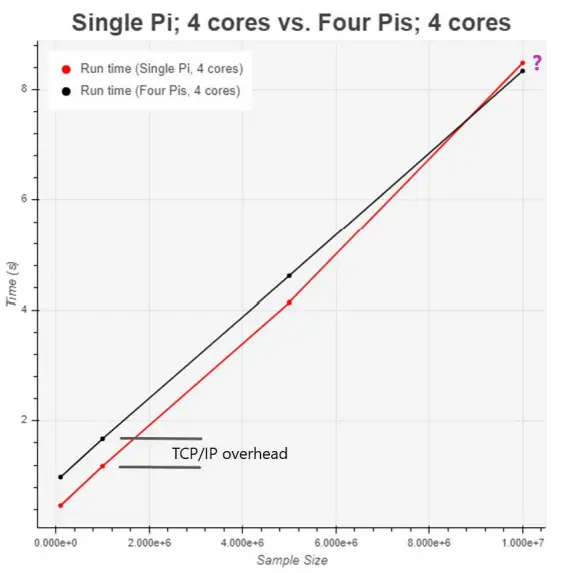
In order to assess the impact of data conversion and transfer, we partitioned a Monte Carlo simulation into 4 subtasks. We then proceeded to compare the performance of running these 4 subtasks on a single node against running them on four separate nodes (Figure 10). Throughout the experiment, we employed sample sizes of 100 thousand, 1 million, 5 million, and 10 million to gather comprehensive data for analysis.
The results, as depicted in Figure 11, aligned with our expectations for the first three data points. The overhead associated with data conversion and transfer led to increased runtimes when distributing the subtasks across the network. However, the outcome for the final simulation, with a sample size of 10 million, proved to be surprising. Distributing the 4 subtasks across different nodes actually outperformed processing all 4 subtasks on a single node. One plausible explanation for this phenomenon is that for computationally-intensive tasks, particularly those with large sample sizes, a single RPi generates a substantial amount of heat, resulting in thermal throttling and slowdown. By distributing the subtasks across the network, this thermal issue would likely be alleviated. Unfortunately, due to time constraints, we were unable to validate this hypothesis thoroughly.
4.2.2.2. 16 cores vs 4 cores
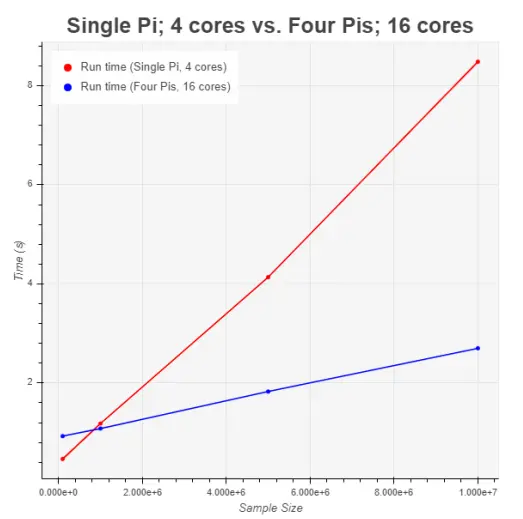
In the final experiment, the objective was to showcase the advantages of a fully distributed and fully parallel system, where all available computing resources were maximally utilized. To achieve this, we conducted a comparison between the performance of running 16 subtasks across the network and the performance of running 4 subtasks on a single node (Figure 12). This comparison aimed to highlight the efficiency and scalability achieved when distributing the computational workload across the entire network.
The results displayed in Figure 13 demonstrate a remarkable improvement in runtime when the other 3 nodes actively participated in sharing the computational workload. Specifically, for a sample size of 10 million, the runtime was enhanced by nearly a factor of 4, signifying a significant boost in performance and efficiency achieved through full distribution and parallelization of tasks across the network.
4.3. Challenges encountered
Initially, we faced challenges during the installation of software packages. Our initial approach involved attempting to compile most packages from their source code, a process that proved to be exceedingly laborious and error-prone. This led to multiple compatibility issues caused by missing dependencies, which ultimately necessitated reformatting the SD cards and reinstalling the operating systems. Subsequently, we discovered a more efficient solution by utilizing the Advanced Package Tool (APT), which streamlined the package installation process by automatically installing packages in standard directories and handling dependencies. The trade-off, however, was a reduction in customizability compared to the manual compilation approach.
Another obstacle we encountered was related to the power supply for the RPis. Initially, our power sources were capable of delivering only 1.1 A to each RPi, which proved insufficient to sustain the execution of computationally-intensive tasks. Consequently, our master node kept experiencing reboots whenever we attempted to run such tasks. We eventually resolved this issue by switching to more powerful power sources capable of delivering 2.0~2.5 A to each RPi, ensuring stable and adequate power supply for all devices.
5. Conclusions
We successfully assembled and tested a 4-node computing cluster using Raspberry Pis. Through this cluster, we effectively demonstrated the benefits of parallelization and distribution of tasks and data. Our cluster represents a robust and cost-effective distributed system suitable for various training and research endeavors in parallel and distributed computing.
Looking ahead, our future plans involve scaling up the system to accommodate hundreds of processors. To achieve this expansion, we will need to design a physical structure capable of housing the RPis securely, while also ensuring a reliable method of delivering sufficient power to the entire system. Additionally, we will explore optimization possibilities for this prototype, such as utilizing a more compact operating system or adopting a more performant programming language to further enhance the system's efficiency and capabilities.