
Introduction
We live in uncertain times. The list of environmental problems seems to grow, while the solutions feel increasingly out of reach. But daunting as it may be, it is imperative that we address these issues. The earth is, in the words of Carl Sagan, “the only home we've ever known.” To not focus our energies on its continued health would be folly and extremely irresponsible both to ourselves and future generations.
One of the most important issue to address today is climate change. This fact becomes increasingly harder to deny as the scientific consensus closes in [1]. Climate change has the potential to cause us great harm in the very near future. It is also extremely complex, and making predictions for the future has proved both challenging and controversial. As Garrett et al. [2] pointed out in their analysis of climate change effects on plant ecosystems, making an effective prediction “requires consideration of a wide range of factors.” The earth is a dynamic system with innumerably variables to be measured. Making an accurate assessment of our environment will necessitate collecting and modeling large amounts of data from many different fields of scientific research [3].
While our technical capabilities have been increasing, there are still other limitations that we face. Scientists can’t be everywhere at once constantly collecting data. Recently in the United States, the politicization of the issue has led to fears that government data might be suppressed. Technology, utilized by non-specialists, those of us not formally trained, can help fill the gap. This project aims to provide a process by which individuals and groups can make meaningful contributions to the record in the form of environmental observations, gathered and recorded by affordable and accurate instruments which can be deployed by non-specialists.
1.1 Environmental sensors
New technologies, such as robotics, can allow us access to areas that might otherwise be off limits, while automated sensors enable us to take measurements “at rates hitherto impossible to achieve.” [4] We now have the capability, if we chose, to take a measurement every minute for a year. This kind of monitoring gives us a much clearer picture of the world by allowing us to capture the effects of episodic or extreme events [5]. To know how a system behaves at all times provides a full picture of the system and establishes a threshold of healthy vs. unhealthy for systems that very often have a degree of natural variability.
There are many scientific organizations employing environmental sensors, monitoring everything from arctic temperatures [6] to pollution levels [7]. In measuring the health of our planet, a very important indicator is the health of our water systems, including our oceans, lakes, and rivers. In 2005, a network of limnologists, scientists studying lakes, created the Global Lake Ecological Observatory Network, or GLEON. Members of the GLEON network employ many different types of sensors, measuring lake data all around the world. The GLEON network now includes over 600 members in 51 countries [8].
Of course, simply collecting the data is not enough. The data must be interpreted, and a single scientist looking at a single lake is very limiting. By linking scientists together under a common goal, GLEON hopes to address another issue among scientists, which is that of data sharing and accessibility. All data collected by the GLEON network is available to all other GLEON members. There are also annual meetings, where scientists from around the world gather to share and collaborate.
Here in the Hudson Valley we have access to an impressive historical environmental record, thanks to the Smiley family, owners of the Mohonk Mountain House. Starting with the original owners, Albert and Alfred Smiley, the Smiley family has kept extensive records of the flora and fauna as well as
weather data going as far back as 1896 [9]. In the 1970's, the Mohonk Preserve also began collecting lake data. The lake measurements were taken twice daily, which continues to this day. Because the resources of the researchers are limited, much of this data collection is delegated to volunteers.
Ensuring that these measurements are recorded accurately every day, twice a day, can be a very challenging task.
In the hopes of reducing this burden on the researchers, Mohonk Lake was recently established as a GLEON site [10]. We are now in the process of installing an extensive system of automated sensors at the lake, measuring weather and lake conditions. Once the setup is complete for the automated sensors, we will have real time data, with measurements taken every fifteen minutes, available to both the researchers and the general public. This will improve the quality of the data collected, and also free resources for other research.
1.2 Citizen science
Another important aspect of the Mohonk Preserve is the citizen science program. This involves having trained volunteers assist in collecting data on plants, animals, and climate. Citizen science is becoming critically important in many areas of research [11]. This is especially true when studying large and dynamic systems, such as the ecosystems of our own planet. One area where citizen science has had an enormous impact is on ornithology, the study of birds. Organizations such as the Audubon Society have been able to muster thousands of volunteers to record their observations through programs such as the Great Backyard Bird Count [12]. Lake ecologists hope to be able to do the same.
Members of the GLEON community have recently created Lake Observer, a mobile app for collecting lake data. The app allows anyone with a smart phone or tablet, anywhere in the world, to submit data to a public database. The app collects data related to water quality, weather, and aquatic
vegetation. By putting this tool in the hands of the general public, lake scientists will have access to data from all across the globe. Users of the app might be anyone from academics to lake enthusiasts, or even local fishermen. There are many people that stand to benefit from the health of our planet's lakes, and the Lake Observer project hopes to give them an opportunity to join in the efforts.
1.3 Interdisciplinary learning
The role of technology is becoming increasingly important for all types of science. Ecology is no exception. Mobile apps such as Lake Observer and environmental sensors can be powerful tools for scientists, but only if they know how to use them. Depending on the complexity of the technology, it will often require assistance from people specifically trained in their use, and each step in the process might require people trained in a variety of disciplines.
In the example of deploying sensors, it is unlikely that an ecologist would have a full understanding of the software and hardware involved. A programmer would need to be brought on to help manage databases and other software and programming needs. Should anything go wrong with the sensors, it is very likely that an information technologist would need to be called on to help diagnose any sort of hardware or networking issue. When the sensors are finally deployed and the data collected, it must also be modeled and presented in such a way that the scientists are able to interpret it. It can often be a challenge for people of various backgrounds to communicate when they may be using a very different set of vocabulary. For this reason, it is helpful to encourage interdisciplinary learning and collaboration early on to help narrow this gap.
1.4 Spatial variability in ecosystems
The set up for the majority of the GLEON sites involves a single buoy deployed at a lake with a
series of precise sensors attached. However there are spatial limits to data collection at a single location in a lake and it might not give a complete picture of the entire lake ecosystem. There is a certain amount of variability throughout an ecosystem [13]. For this reason, it is beneficial to take reading from multiple points in a lake. This presents somewhat of a challenge, when attempting to take measurements from multiple points but within the same time frame. One could deploy multiple sensors, but depending on the size of the lake, this might require ten or more sensors. Due to the cost of many sensors, this would be a serious limitation to many studies. The proposed framework in the following pages aims to address this cost limitation.
1.5 DIY sensor project
Environmental sensors have been used by scientists for some time now, but it is only within the last ten years or so that the cost has made them available to the average consumer. There are now thousands of hobbyists tinkering with robots and sensors, building complicated and often very functional projects [14]. The need for a low cost sensor may have been here for a long time but it is only recently that it has become feasible.
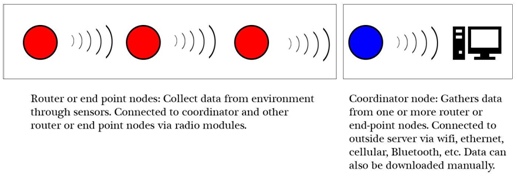
The basic concept of the mesh sensor network is illustrated in Figure 1.1. The framework for this project was built using Raspberry Pi computers, which are very small, single-board computer that can be purchased for less $40 each. The Pis are networked together using XBee radio modules. XBee radios have the advantage of being small, inexpensive, long range, and low power. The Pis are powered by a solar array and rechargeable battery. Various sensors can be attached to the Pi, reading data into a database, which is then passed through the network to a main coordinator node. The data can then be downloaded in any number of ways (e.g., Wi-Fi or Bluetooth). Not including the cost of sensors, which
can vary greatly depending on the sensor type, each unit can be built for about $200. Compared with
the cost of many prepackaged sensors, this is an order of magnitude lower.
One of the main goals of this project is to make sensing systems available to a wider audience, which may include graduate and undergraduate researchers, or even hobbyists. Deploying ten or more sensors suddenly becomes feasible to many academics or researchers. The other objective is to encourage interdisciplinary learning. While an affordable sensor framework is possible, there are few people building such frameworks, likely because of the disconnect between ecologists and programmers.
The function of the framework would be most useful to an ecologist, but the process of building the sensors may be outside their normal comfort zone. Given time and motivation, anyone with a reasonable understanding of computers would not be able to follow the guidelines presented. However, in an ideal situation, implementation of this framework would involve biologists, who would set the goals of the project, electrical engineers to work with the hardware, and computer scientists to deal with the programming. If students and academics from different disciplines were able and willing to collaborate on a project they might find that the arrangement is both interesting and beneficial to everyone involved.
Assembly and configuration
2.1 Hardware options
Much of the relevant technology that is available today was either unavailable or unaffordable ten years ago. This brings benefits and challenges. With so many options to choose from, there should be a solution to nearly any problem, and having numerous ways to address a problem gives us the freedom to find a solution that best fits our needs and resources.
However, having more technology increases the learning curve and requires constant vigilance to stay current. In some cases, particularly with new technology, the documentation might be limited, making implementation and learning difficult. Having numerous choices also requires a considerable amount of time spent weighing options. There is also the risk of investing time and money into a piece of equipment only to find that it is not well suited to its intended purposed. Similarly, with the rapidly changing technological environment, it is possible that some new technology might come along to make some piece of equipment currently being employed impractical or inferior, forcing an additional time or monetary investment into the project.
2.1.1 Arduino and Raspberry Pi
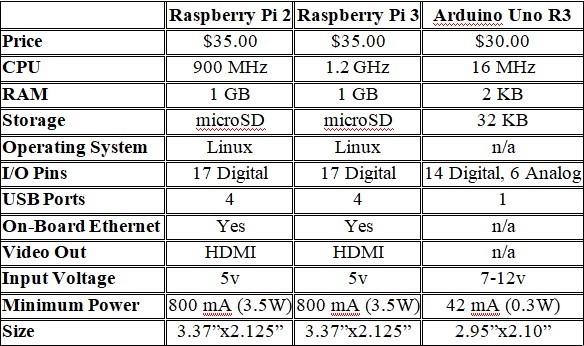
In selecting a base processor for this project there were two main choices, the Arduino and the Raspberry Pi. Both are small (about the size of a pack of a smartphone), affordable, and capable of interfacing with a wide variety of hardware, and both are frequently used for remote sensing (see Table
2.1 for comparison). The Arduino is a micro-controller, not a full computer, which means it
is capable of running a single program, over and over again. The Arduino uses its own specific
programming language and has a reputation for its simplicity and ease of use. It is popular with roboticists and hobbyists, and for that reason it tends to be very well documented. Gandra et al. [15] were able to build a very affordable framework for ecological sensing using Arduino.
I elected to use the Raspberry Pi for this project because it would allow for a wider variety of programming options. Raspberry Pi differs from Arduino in that it runs a full Linux operating system, making it a fully functional computer rather than simply a device for interfacing with other hardware. Having a full operating system offers somewhat more power and freedom compared with the Arduino. The Arduino and the Raspberry Pi are able to interface with each other, so it is possible to use both in a single project, perhaps having the Arduino interface with the sensors and then having the Pi handle the data processing and computations. While the Raspberry Pi might require more initial configuration than an Arduino, it also allows for the possibility of automating a lot of user setup using bash and Cron scripts.
2.1.2 XBee radio modules and networks
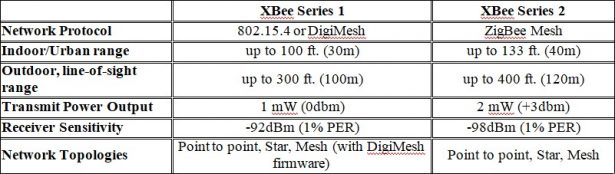
XBee is a series of radio modules. These modules transmit serial data and are able to interface with the Raspberry Pi's GPIO port. There are also USB adapters available which allow the XBee to plug directly into the Pi's USB port. There were two different models considered, the Series 1 and Series 2. They each have differences in communication protocols, network topology, range, and power consumption (see Table 2.2).
The first two things that one should consider are range and power consumption. In a side-by- side comparison, the S1 and S2 both perform comparably, and reasonably well, for our particular need. Power consumption is minimal, and range is up to 120 meters in ideal conditions. It should be noted that the Series 1 and Series 2 are both available in “Pro” versions, which have a much extended range, up to one mile. However, they also consume significantly more power, about 60mW compared with just 2mW for the regular modules. Since we were trying to limit power consumption, and because the normal range was enough for most situations, the Pro versions were not considered for use.
The second point considered, and the main difference between the S1 and S2 modules, was the type of network protocol that they employed. The different types of topologies available with the XBee
are: point-to-point, star, and mesh (see Figure 2.1). In a point-to-point network, each module is configured to communicate with another single module based on its specific address. A module can be reinitialized to communicate with a different device, but the modules are paired with
one, and only one, other device. A module can also be programmed to broadcast to every other module in range. This is the star topology, with several modules all connected to one central node (Figure 2.1). The third type of topology, and the one used here, is the mesh network (Figure 2.1).
A mesh network is one where several nodes, known as routers, are able to receive data and also send that data to one or more other routers. By default, the S1 modules use the 802.15.4 protocol. This protocol only allows for point-to-point communication under normal setup or star networks via broadcast. However, there is an additional firmware available, known as DigiMesh, which does allow for mesh networking. The S2 modules, by contrast, can only run the ZigBee mesh firmware.
While both the S1 and S2 are capable of mesh networking, there are several differences in their structure and functionality (see Table 2.3). On a ZigBee network, each module must be loaded with firmware which will assign it one of three possible roles: coordinator, router, or end point. Every network must have one, and only one, coordinator, which is able to send or receive data from other
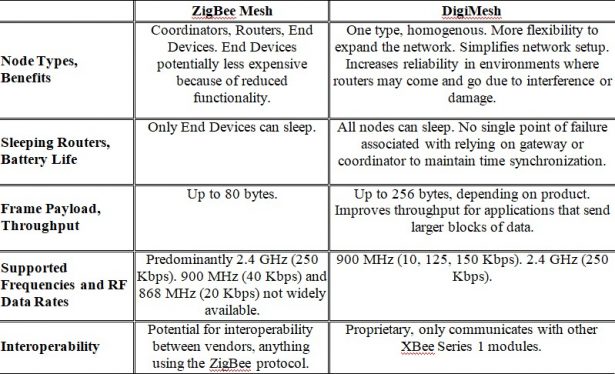
nodes and is responsible for maintaining the network. If the coordinator goes offline, the network will fail. Routers are able to send or receive data from other nodes. End points are only able to send data. Because of the reduced functionality of the end points, they also require less power. On an S1 mesh network, there are no roles assigned to the nodes. Every node is equal. This gives the network some additional flexibility to expand and reconfigure if nodes are lost due to damage, interference, or power loss. There is also an advantage in power consumption as every node can enter sleep mode, whereas on an S2 network, only the end point nodes are capable of sleeping. In the end however, I chose to use the S2 modules, mainly because there were more software libraries available and the documentation was much better compared to that of the S1, specifically in terms of programming a mesh network.

(E) GPIO Breakout Board, (F) ADS1115, (G) XBee mounted on breakout board, (H) Ribbon Cable
2.2 Setting up the Raspberry Pi
The basic setup of the Raspberry Pi is very straightforward. For detailed instructions, refer to Section 1 of Appendix A. Once the operating system is loaded and configured, the Raspberry Pi functions just as a normal Linux computer. There are USB ports available for attaching a keyboard or mouse. There is an Ethernet port built in, or a Wi-Fi module can be attached, and there is an HDMI video output.
The Raspberry Pi also has a row of GPIO (general purpose input/output) pins. It is through these pins that we are able to connect other hardware components, such as sensors, to the Pi. The pin- out will be different depending on the model of the Pi, and aside from the input/output pins there will also be several pins for power and ground. While it is possible to connect some things directly into the GPIO pins, it is more common, and preferable, to work through a solder-less breadboard. A Raspberry Pi can be connected to a breadboard using a series of jumper cables but there are also specific pieces of
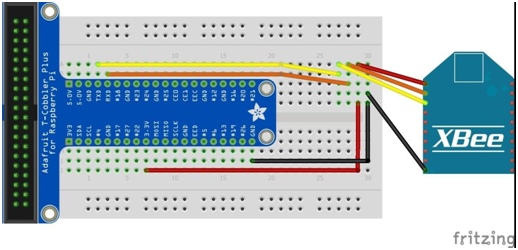
hardware known as breakout boards, which simplify the connection process. Using a breadboard and breakout board it becomes trivial to connect any number of components to each other and to the Raspberry Pi in an organized and contained package (Figure 2.2).
2.2.1 Configuring the XBee
The XBee modules need to be configured before being attached to the Pi. For instructions on configuring the XBee, refer to Section 8 of Appendix A. The XBee is wired to the Pi by connecting the data receiver on one (Rx) to the data transmit on the other (Tx) and vice versa (Figure 2.3). Aside from the various operating roles of routers, coordinators, and end points, there are also two different operating modes: AT and API. In the case of this project, we had one node set to coordinator API, and two nodes set to router API.
There are several key differences between AT and API mode. AT refers to “transparent” mode. In transparent mode, a router will send data to the coordinator, and the coordinator will read that data exactly as it was sent. However, the data will often be sent in several packets. In the case that there are
multiple nodes in the network, the coordinator might be receiving data from several nodes at once, which could end up with received messages being jumbled. For this reason, any network involving more than two nodes should be using API mode rather than transparent. API mode allows the addition of supplementary data to a packet, such as checksum and destination address. It also allows for the reprogramming of other nodes in the network, such as setting an end device into sleep mode.
2.3 Powering the Pi
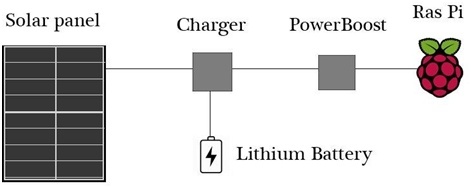
In most cases of deployment, it is necessary to power the nodes by some means other than AC power. The most convenient way in the majority of situations will be solar power. In the example of data buoys out in a lake, the sensors would generally be in full sunlight, which is ideal for solar power. There are several options available for providing solar power to a Raspberry Pi. The hardware used in this project included a solar array, which was connected to a charging module, which was connected to both a rechargeable lithium battery as well as a USB power supply (Figure 2.4).
Sunlight is not always reliable as there may be a series of overcast days. One critical point about
an XBee mesh network is the importance of the coordinator. If the coordinator goes offline then the entire network will fail. For this reason, if at all possible, it is preferable to keep the coordinator on AC power rather than solar. That being said, the Raspberry Pi consumes about 3.5W of power in normal operation and so it is entirely possible to gather enough power from the sun to power the Pi. However, power consumption should be taken into consideration and minimized wherever possible.
There are many battery sizes available depending on the power needs of the setup. The battery in this project was a 2500mAh lithium ion, but batteries at 4400 and 6600mAh are also commonly available. As mentioned previously, the XBee modules use very little power and if the network consists of several end devices it is possible to place them in sleep mode and reduce the power consumption even further. Another piece of hardware that can be useful to add to the sensors is a GPS. It is possible to simply note the GPS location of each sensor at deployment time, but it might be preferable for some to read the GPS information directly to the Pi and write it along with the sensor data. As a GPS can draw quite a bit of power, and because the sensors are not likely to be moving, it is
unnecessary to keep the GPS running constantly. Rather, the GPS can be programmed to take a reading once a day, or once a week, or at whatever interval seems appropriate.
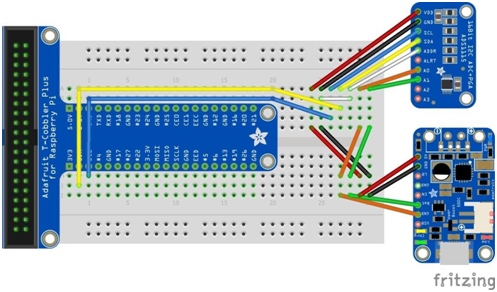
In the case of a solar powered Pi, it can be very useful to know the current voltage of our battery. In the event that the power is getting low, this can give us the opportunity to respond, perhaps by disabling certain non-essential functions. The signal coming from the battery is an analog signal. However, the Pi is not able to read analog data, so an analog to digital convert (ADC) is required. The ADC took a dual channel reading from the PowerBoost, measuring the voltage difference between the
battery and ground signals and passing the reading to the Raspberry Pi (Figure 2.5).
2.4 Attaching sensors
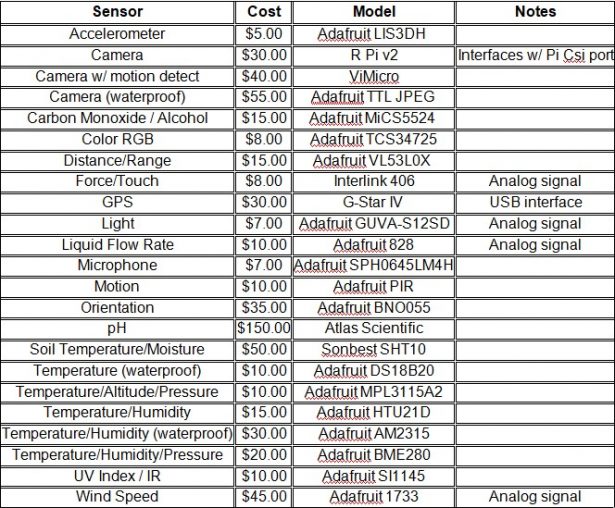
There are any number of sensors available for the Raspberry Pi, allowing for the collection of many different kinds of data in many different environments. As the mechanisms required for measuring different variables can be quite different, there is also quite a bit of variation in the price of sensors. Table 2.4 lists some of the more commonly available sensors and their approximate cost. In some cases, the same sensors are available in either weatherproofed or non-weatherproofed versions. There are also several options available for weatherproof enclosures for the Raspberry Pi, although depending on the severity of the environment to which Pi will be subjected, it is just as common for many hobbyists to craft their own enclosures from common materials such as plastic containers, or even a water bottle.
There are also differences in how the sensors interface with the Pi. The sensors used in this project were very simple 3-wire temperature sensors. They simply require power and ground, and connecting the signal wire to one of the Pi's digital inputs (Figure 2.6). These sensors are also capable of running in parallel allowing any number of these temperature sensors to be wired together. Because the unique serial number of each sensor is recorded with each reading, the Raspberry Pi is able to differentiate which signal is coming from which sensor. While many sensors might interface easily with the Raspberry Pi, others might require the use of breakout boards. A breakout board is a piece of hardware that simplifies the process of connecting any device to a breadboard. Any piece of hardware will have some number of pins or wires that need to be connected to the Raspberry Pi. The spacing of the pins is not often such that the device can plug directly into the breadboard. The breakout board provides this correct spacing, keeping the setup clean and organized. Another difference among various sensors is how they transmit data. Some sensors only record analog data, and since the Pi only reads digital signals, an ADC is needed to convert the data signal into data that that Pi can read.
Programming and setup
As the Raspberry Pi is a full Linux computer, the programming for the sensor network could have been done in any number of languages. The two choices that I considered were Python and Node.js. Python is a versatile general purpose programming language which includes an impressive standard library and a vast array of outside packages available. Node.js is a more recent language than Python but has already obtained a very strong following.
3.1 Node.js
Node.js is an open-source, event-driven JavaScript runtime environment. It has become very popular for web applications, as the event-driven interface is well suited to the user interaction of websites, and presumably because most web designers were already coding with JavaScript. It makes use of non-blocking asynchronous I/O and callback functions. When performing tasks that could take some time to complete, such as taking a reading from a sensor, it is necessary to employ asynchronous functionality. A callback function is a simple way to build asynchronous functionality into code. The callback is defined as an anonymous function and passed as a parameter, along with any additional parameters, when calling a function that includes a callback (Figure 3.1).
Like Python, Node.js has a large collection of open source libraries available. These packages can be added to Node projects using the node package manager, or npm. Every piece of hardware that I used for this project had at least one npm package available. The number and variety of npm packages greatly reduces the programming work involved when incorporating devices into a project.

3.2 MySQL
There are at least two popular database options today, MySQL and MongoDB. MongoDB is what is known as a NoSQL database and the structure of the database is similar to what a programmer might think of as a dictionary, with key-value pairs. NoSQL databases may have an advantage over relational databases when complicated object relations are involved but since the database for this project was a simple one I chose to use MySQL.
MySQL is very easy to install and configure on a Raspberry Pi. See Section 5 of Appendix A for detailed setup instructions. There is an npm package available which makes interacting with a MySQL database very easy. For some example code, please refer to write_db.js in Appendix B.
The database structure is very important to consider for any project. The requirements for this project include being able to identify which node is sending the data, knowing the geospatial location of the node, knowing which sensor the data is coming from, knowing the voltage of the Raspberry Pi if it is solar-powered, and knowing some other general information about the node and the
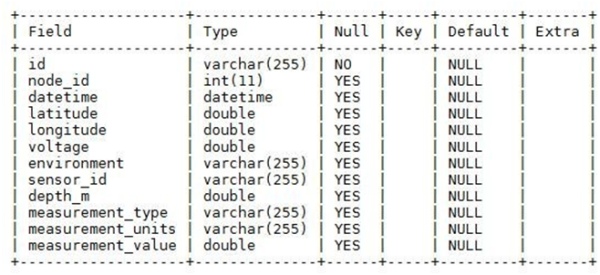
sensor. Some of the database structure was modeled after the water quality data that is collected from the Lake Observer app, which includes the depth of the measurement if immersed in water, the measurement type, measurement units, and of course measurement value. This will allow us to use the same table structure regardless of what kind of sensor we are using. The full database structure is illustrated in Figure 3.2
3.3 Reading devices
The npm libraries enable us to easily interface with a huge number of devices. All of the device readings in this project are asynchronous, including temperature sensor, the analog-digital converter, and the GPS. In some cases there will be more than one library available, allowing us to choose the one that best suits our needs, and of course there is always the option to building a custom library.
The temperature sensor used in this project was a very simple 3-wire sensor, requiring minimal wiring to connect to the Pi and using very straightforward code to interact with and read from the sensor. Refer to read_temp.js in Appendix B for some example code. The value returned from the temperature sensor looks like [sensor_serial#, sensor_reading]. The serial number was entered into the database as the serial_id, which in the case that we have multiple sensors attached in parallel to a Raspberry Pi we would know which reading came from which sensor.
The analog to digital converter used in this project, ADS1115, is a 4-channel converter, meaning that it can read from up to four different devices. It uses I2C, which is a communication protocol that allows one chip to talk to another. It can take both single-ended or differential readings. A single-ended reading will measure the voltage between the analog input channel and the analog ground. A differential reading uses two channels and measures the voltage between those two channels. For this particular project setup I took a differential reading between the battery and ground signals coming from the PowerBoost 500 module. The readings, taken in millivolts, were converted to volts. For some example code refer to measure_voltage.js in Appendix B.
Use of the GPS module with the Raspberry Pi requires the installation of gpsd. Section 7 of Appendix A outlines the installation and use of gpsd. By default, gpsd will start a GPS daemon automatically when the Pi starts up, which will query the GPS when it is available. Since we are trying to minimize power consumption it is better to disable the automatic daemon startup and instead start and stop the daemon from code. Refer to gps_check.js in Appendix B for example code implementing the GPS. The code will query the GPS and then write the latitude and longitude to our configuration file, which can then be read by the other modules.
3.4 Reading and writing files
It will often be useful to read or write files, and Node.js is capable of doing either one in a fairly straightforward manner. Reading files is done asynchronously. In this project I made use of two configuration files; router.conf and coord.conf. These configuration files contain information that is user-specific, or values that might vary from one node to another, such as database values, sensor values, and node values. Refer to router.conf in Appendix B for an example configuration file.
File writing is performed, as mentioned earlier, by the GPS, which writes the latitude and longitude to the configuration file. File writing was also employed the coordinator node, which backs up the database values and exports them to a csv file. That csv file is then sent to a remote server. Refer to db_to_csv.js in Appendix B for example code.
3.5 Sending data to a remote computer
The data recorded by the sensors is only useful if it can be accessed. In the case of an extended deployment, it is often preferable to have access to “live” data. This of course requires that the coordinator node, which contains the data from all the other nodes, has some form of access to an outside server. In the deployment of this project, the coordinator node was connected to the internet and so that data can be accessed at any point. When sending data from a local machine to a remote machine there are a number of options available, such as sftp, scp, and rsync.
Accessing a remote machine will requires logging to that machine with the necessary credentials. In order to do this in an automated way ssh keys will need to be used. An ssh key is a way for a remote machine to know that the machine which is asking permission for access does indeed have permission. This will allow us to send commands via ssh or scp and not be prompted to enter a password. Installation of ssh keys is outlined in Section 11 of Appendix A. Once the ssh keys are established we can then automate a connection to a remote host so that data is transferred at some specified time interval. That time interval is established using Cron jobs.
3.6 Cron jobs and bash scripting
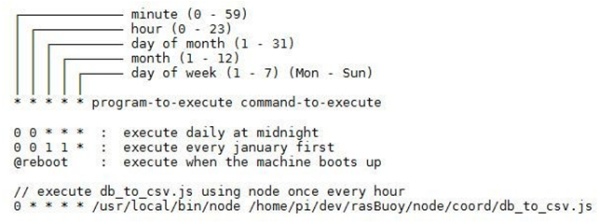
One of the benefits of working with Raspberry Pi is having access to a full Linux operating system, which includes things such as Cron jobs and bash scripting. Cron is a scheduling agent that allows for the execution of any program or script at a particular time interval. Cron can specify the minutes, hours, days, or months. Figure 3.3 shows the form that a Cron job takes as well as a few examples. Section 10 of Appendix A lists all of the Cron jobs that were used for this project. The main router and coordinator scripts were both run using Cron.
Bash scripting is a way to encapsulate any Linux command into an executable program. A bash script was used to run a series of scp commands which would send several csv files to a remote system. The bash script was executed once every hour using a Cron job. The bash script used, send_data.sh, can be seen in Appendix B.
3.7 XBee
The code controlling the XBees was different depending on the role of the sensor node. For the coordinator node, the main Node.js file, coordinator.js, is run at boot time. The program will wait to receive data from other nodes. Any data received will be entered into the database. The database is then converted to several csv files every hour via Cron jobs and sent to a remote machine. The csv files are then read by that machine and displayed in a web portal.
The main router file, router.js, is also run at boot time. It will also listen for data. Any data received is checked against the database to see if the data has already been received. In a network with multiple routers connected and passing on data it is possible for the same piece of data to wind up at the same router more than once. If the data is new it will be saved to the database and then sent out to the other nodes. Aside from listening for data, the router will also record data every fifteen minutes, save it to the database and send it to the other nodes. It is also possible for a router to be programmed to act as an end device, only recording and sending out data, but not receiving data.
Deployment and results
Whenever writing code, it is imperative that the code be thoroughly tested somewhere along the process. When assembling hardware, we must similarly test the functionality of the setup. In the case that we are testing both the hardware and software there are additional challenges. Because everything must interact and function together, if things don't work as expected, it is not always readily apparent if the problem is hardware or software related. This project is an amalgamation of many different pieces and a successful deployment of the project must make sure that all those pieces fit together properly.
4.1 Initial deployment setup
The initial deployment of the framework was a very simple proof of concept deployment. There were several goals of this initial deployment. The first goals were related to the programming. The intended function of the code was to read data from the sensors, write the data to a database, and send the data to the other nodes in the network. The second set of goals were related to the functionality of the hardware itself. The various pieces of hardware each had separate roles to play; reading environmental data, transmitting data between nodes, measuring voltage, and sustaining power.
- Nodes and roles
The full setup included three Raspberry Pi / XBee nodes; one coordinator, one router, and one end device. The coordinator was hooked up to AC power and also connected to the internet via an Ethernet cable. The router node was being powered from a solar array and set read the temperature from a sensor every fifteen minutes. It was also hooked up to ADC and set to read the voltage from the
battery at the same time that it reads the temperature. The end device was also on solar power and set to read the temperature from a sensor every fifteen minutes. Both the router and the end device were positioned in full sun in a south facing window. The solar array does not have optimal function behind a window but an important part of testing the framework is to test it in less than optimal conditions, as it should be expected to sustain power on cloudy days as well as overnight when it will be receiving no solar charge at all.
- Data flow
The data is read from the sensors of the router and end device, with each node recording the sensor data to their own local database. After writing the data it is broadcast to all other nodes in range within the network. In this case, all nodes were within range of each other. The router will receive incoming data, write that data to its database, and broadcast that data again out to all nodes in range.
Whenever data is received by a router or coordinator it will be checked against the data already within its database. New data will be written to the database, and in the case of the router node, the data will be broadcast to the other nodes.
The coordinator node records all received data in its database. Barring any kind of failure in the routing, all data in the network should ultimately make its way to the coordinator so that its database contains all information recorded from all other nodes. Selected data is then read from the database and written to csv files every thirty minutes. In this deployment there were four separate csv files; one file for the temperature readings from Node 0, one for the temperature readings from Node 1, one for the voltage readings from Node 0, and one for the most recent temperature and voltage readings from both nodes. All of these csv files are then sent every thirty minutes to a remote server.
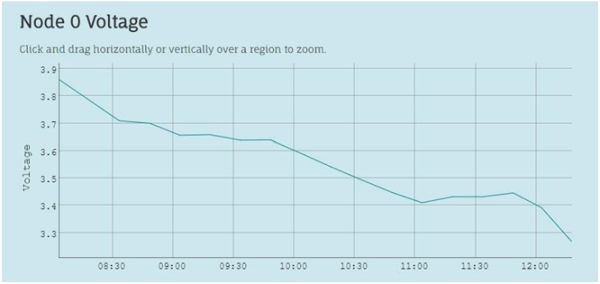
- Data view
After the data is sent to the remote server it is then published to a web site. With the data being refreshed every thirty minutes, the result is effectively having a live display of the sensors. This is one of the benefits of having a coordinator node connected to the internet. While it is not a necessity to have a live feed of the sensor data, it is certainly beneficial in many cases. The csv files that are received by the web server are displayed graphically using a simple JavaScript based web widget, which also allow for zooming into specific time periods (Figure 4.1). Aside from the graphical displays there is also a tabular view showing all the readings available from the various sensors as well as the timestamp for the data (Figure 4.2).
Source: Creating a mesh sensor network using Raspberry Pi and XBee radio modules