
DSP Group, a leading global provider of wireless and voice-processing chipset solutions has introduced a low-power AI/ML-enabled dual-core SoC called DBM10.
According to the CEO of the company, almost all edge applications for AI require the ultimate as regards low power, small form factor, cost effectiveness, and fast time-to-market. So it’s with great enthusiasm that they bring DBM10 to the desk of their customers and partners.
Our team has worked to make the absolute best use of available processing power and memory for low-power AI and ML at the edge—including developing our own patent-pending weight compression scheme—while also emphasizing ease of deployment. We look forward to seeing how creatively developers apply the DBM10 platform.
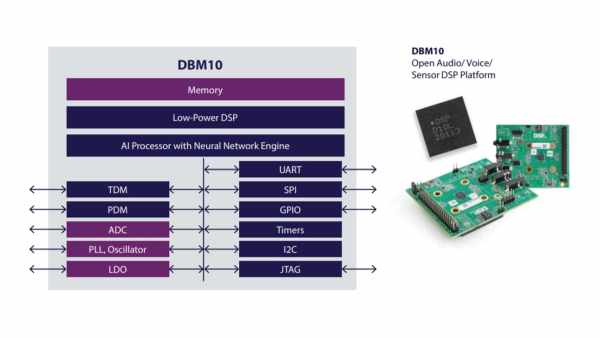
DBM10 AI SoC is a high-performance and low power chip with Digital Signal Processor and dedicated nNetLite Neural Network Engine. It is designed to improve voice and sensor processing and also ensure that consumption is low when working with sufficient-sized neural networks.
DBM10 is supported by an embedded memory along with serial and audio interfaces that make it easily compatible with many external devices, including application processor, codecs, microphones, and sensors. It is well suited for wearables, tablets, smartphones, true wireless stereo headsets and smart home gadgets like remote controls.
Features of the DBM10 AI SoC include:
- SPI and I2C serial interfaces
- Universal Asynchronous Receiver Transmitter for serial communication
- PDM and TDM audio interfaces
- General Purpose IOs for MCUs and peripherals
- 32-bit timer
- Watchdog timer
- Low-power ADCs for analog microphones
- JTAG for debugging, and,
- 48-pin Quad Flat No-leads package, and,
- Suitable for AI voice-based applications.
Specifications of the neural network processor:
- Has a compact form factor of about 4 mm x 4 mm
- Has ~ 500 µW ultra-low-power inference consumption for voice NN algorithms
- can run “Hello Edge 30-word detection” model @ 1 MHz (125 MHz available)
- allows porting of large models, typical about 10s of megabytes, without significant accuracy loss using model optimization and compression.
Read more: DBM10 – LOW-POWER EDGE ML/AI SOC WITH DSP AND NEURAL NETWORK ENGINE